

KV Cache Chunking in LLMs: How Modern AI Systems Reduce Memory Waste by 80% and Boost Performance 4x
By Nejla Tessa AYVAZOGLU
Founder & AI Engineer, VirtexAI

What if up to 80% of your GPU memory is being wasted — without you realizing it?
This is not a model problem.
It’s not a hardware problem.
👉 It’s a memory design problem.
And KV cache chunking is how modern AI systems fix it.
📌 Introduction
Large Language Models (LLMs) power today’s most advanced AI systems — from chatbots to enterprise analytics platforms. However, when deploying these models at scale, the biggest challenge is often not model accuracy, but memory efficiency during inference.
At the center of this challenge lies the Key-Value (KV) cache — a mechanism that dramatically speeds up autoregressive generation by storing previously computed attention tensors.
While KV caching improves performance, traditional implementations introduce a major bottleneck:
👉 inefficient memory usage due to contiguous allocation.
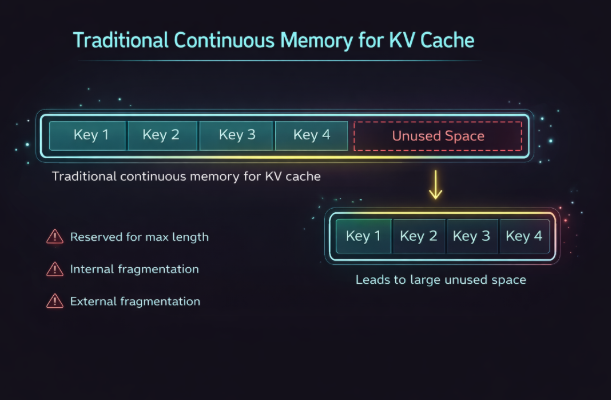
⚠️ The Hidden Problem: Why LLMs Waste Memory
In conventional systems, KV tensors are stored in a single continuous block of memory.
While this design is simple and GPU-friendly, it leads to:
Over-allocation for maximum sequence length
Internal and external fragmentation
Up to 60–80% memory waste
This results in:
Reduced GPU utilization
Smaller batch sizes
💡 The Breakthrough: KV Cache Chunking
Engineers asked a simple but powerful question:
👉 What if memory didn’t need to be contiguous?
KV cache chunking introduces a new approach:
Memory is divided into fixed-size blocks
Logical token order is preserved
Physical storage becomes non-contiguous
A block table maps tokens to memory locations
🧠 Simple Analogy
Think of it like storing books.
Instead of forcing all books into one long shelf (which creates empty gaps),
you store them across multiple smaller shelves and use an index to find them.
👉 That’s exactly what KV cache chunking does.

🔬 Key Insight: Why This Still Works
A common concern:
👉 “If memory is fragmented, does attention break?”
The answer is:
👉 No. It works exactly the same.
Because attention depends on:
Logical token order
NOTPhysical memory layout
This means:
Dot product remains unchanged
Softmax distribution is preserved
Final output is identical
👉 KV cache chunking is mathematically equivalent to contiguous storage.
⚡ Real Impact: Speed, Cost, and Scalability
KV cache chunking delivers massive improvements:
Memory waste reduced to < 4%
Up to 2–4x throughput increase
Larger batch sizes
Better GPU utilization

🧩 System-Level Advantages
This is not just a memory trick.
KV cache chunking enables:
KV cache sharing across requests
Copy-on-write for branching generations
Improved batching and scheduling
Better parallelism
👉 This transforms LLM inference from a memory problem
into a system optimization strategy.
🏗️ Real-World Systems Using This
Modern inference systems already rely on this approach:
vLLM (PagedAttention)
TensorRT-LLM
Triton Inference Server
🚀 Why This Matters for AI Builders
If you are building AI systems, this is critical:
👉 The difference between:
a demo
and a production-ready AI system
is not just model quality —
it’s system design.
💡 Final Thought
KV cache chunking represents a shift from:
👉 “optimize memory usage”
to
👉 “design scalable AI systems”
🧠 About VirtexAI
At VirtexAI, we focus not only on building AI models, but on designing scalable, efficient, and production-ready AI systems.
Understanding system-level optimizations like KV cache chunking is essential for deploying LLMs at scale.